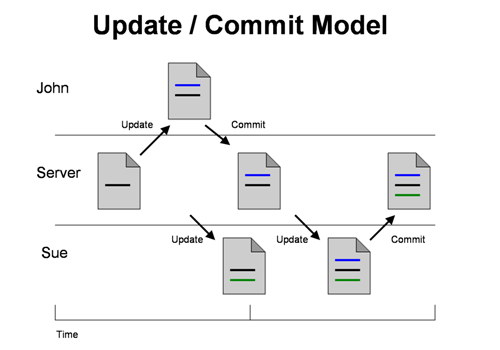
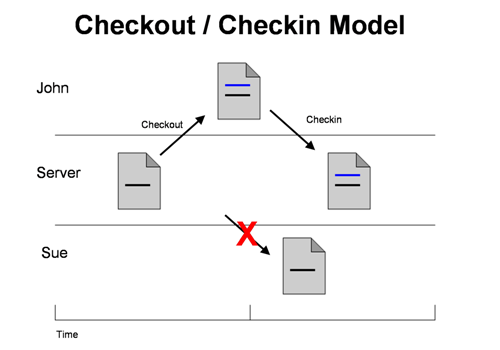
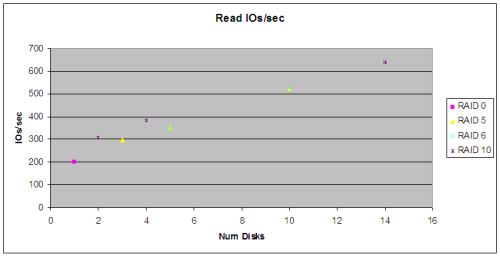
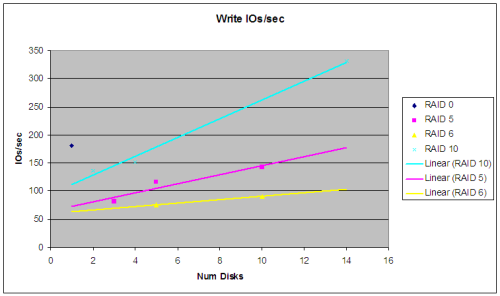
Branch and Merge
Many people who implement Update/Commit typically organize the server into the Trunk and Branches folders:
This allows you work on long term, scheduled features in Trunk, while making unexpected bug fixes in the latest branch: v2.0. The changes in the v2.0 branch can easily be merged back into Trunk using the version control software.
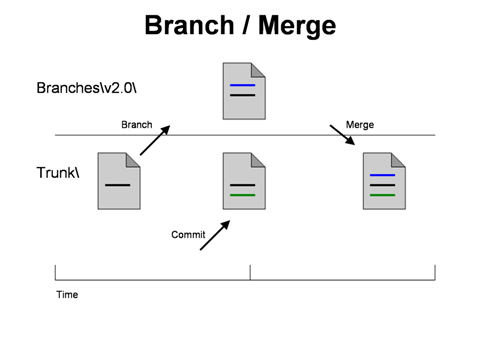
After you release the code and before working on the next feature, you branch your code to the Branches\v2.0 directory. When a bug needs to be fixed in the released version, you
- Fix the bug in the Branches\v2.0 directory (The blue line in the image above)
- Commit the fix to the Branches\v2.0 directory
- Merge (using your version control software) the change from Branches\v2.0 to the Trunk directory, which happens to have a change (green line).
Release Flexibility Problems
Now you have been using update/commit version control and you have released your software and it is being used by end users. The to-do list is growing and some features can be done quickly and some take longer. You can easily find yourself in a situation where some of the long-term features have been committed to the Trunk; however the business has requested a quick feature that they need ASAP. For instance, a new client has changed the priority of a quick feature.
Another problem is that developers commit changes to the code unaware of the current release cycle. You can find that a committed change during testing can delay the release when the committed change should have been held back for a later release. The fundamental problem is that developers “decide” what is included in the release, when this decision belongs to other people, such as a release manager, project manager or the test manager.
The Hack in the Update / Commit Model
There are several ways to address the problems above using the Update/Commit model, but the hack below will lead you naturally to distributed version control.
If you have become comfortable with branching and merging between Trunk and Branches\v2.0, then there is an easy next step to address this problem. Branching and merging each feature:
When a developer starts to work on a new feature, they branch from Trunk to Features\Bar Feature and start working in the Bar Feature folder. When it is decided that the Bar feature is finished and ready for release, they merge the code back to Trunk using the version control software. This allows a manager to decide to release the Bar feature even though the Foo feature is not ready.
Conclusion
Working on features in a branch allows people to decide late in the release cycle what will be included in the release. It also allows flexibility when priorities change in the middle of a release cycle.
The downside is that there will be many Feature folders that are no longer needed because they have been merged back, or have been orphaned. Linus calls these “expensive” branches, since they are intended to be either temporary or private. Distributed version control addresses this…