This is a second entry in a series on SQL Server Analysis Services (SSAS). To see the other blog entries on this tutorial, click on the SSAS Beginner’s Guide on the top bar.
Relational Databases
Let’s take a quick look at a relational database table of football players:
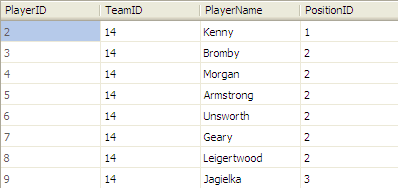
The table is structured in rows and columns. Note that the column names are fixed – they are not based on the data. This is a difference between relational databases and SSAS databases.
SSAS databases are typically loaded from the relational database to the SSAS database and a copy of the data stored in a different form in the SSAS database. Once the data has been copied, you can delete the relational database (This assumes you are using the default MOLAP option).
2 Dimensional SSAS Databases
SSAS databases are stored in multidimensional structures. Below is an example of an SSAS database with just 2 dimensions. This contains fantasy football points, so the “2” in the first row and first column is the fantasy football points that Reina received during the 11/Aug/2007 game week.
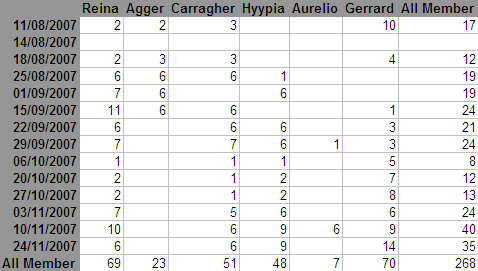
The grey area contains two dimensions: Players and Game Weeks. Each column header (and row label) is called a dimension member. Example dimension members are “Carragher” and “03/11/2007″. These dimension members are similar to column names, however they are based on data.
Each number in a cell is at the intersection of two dimension members. Take for instance Gerrard’s first match where he received 10 points. It is stored at the intersection of
- “Gerrard”
- and “11/08/2007″
Gerrard and “11/08/2007″ are coordinates to the cell containing 10. When you start writing MDX queries, you will try to find ways to reference these cells using coordinates.
The All Member aggregation is what is really useful in SSAS databases. It is a member that is added to each dimension when loading the data. The All Member cells are pre-calculated when loading the SSAS database data and are typically a sum. This member is physically stored and you can also query All Members just like any other member. The All Member aggregation above makes it easy to answer questions like, “What is the total number of points that Gerrard received?” The answer is found at the intersection of
- “Gerrard”
- And the Game Week’s “All Member”.
You can reference the All Members using the coordinate system just like any other member of the dimension.
3 Dimensional SSAS Database
Let’s take a look at a 3 dimensional SSAS database:
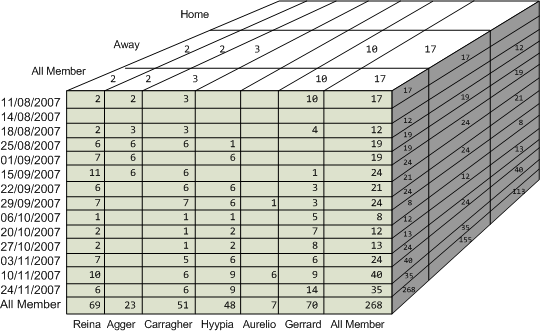
The diagram above shows most of the values stored in the 3 dimensional SSAS database. There are some values in the back of the cube that you can’t see without cutting the cube open, but they still exist.
The cube is shown so that the front pane is the same data as the two dimensional SSAS database above.
Just as a side note, although the diagram has two 10s on the cell for Gerrard on 11/08/2007, on the front in grey and on the top of the cell in white, the cell block itself only contains the number once. The cells can only contain one number and the numbers shown are for the 3D block, rather than a 2D pane. So the cell 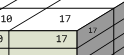 contains just 17, even though 17 is shown three times.
contains just 17, even though 17 is shown three times.
The only difference with 3D cubes is that locating a cell requires 3 coordinates instead of 2:
- Game week
- Player
- Home/Away
The 3rd dimension, Home/Away, gives us more information about the scores compared to the 2 dimensional database. If you wanted to know how many points these players received for all Away matches, you would go to the intersection of these three coordinates:
- Game week’s “All Member”
- Player’s “All Member”
- and Home/Away’s “Away” member
Here you will find the value “155”.
The cube can answer other questions. Although you cannot see it in the diagram, the cube stores total points that Gerrard received at home. You would find it at the intersection of
- the game week’s “All Member”
- “Gerrard”
- “Home”.
This value would be found on the bottom plane just to the left of the value 155.
4 or More Dimensions
There is really no limit to the number of dimensions you can create in your database even though it might be difficult to visualize. Let’s say you want to track sales for the following:
- the year 2007
- the southeast region
- the product “gizmo”
- and the “Acme” store
You may not be able to see how all the data is stored, however this scenario does have 4 dimensions.
